Chapitre 2: Diviser pour régner

{kind=link}
Nous avons vu en première deux algorithmes de tris assez naturels, mais peu efficaces: le tri par insertion et le tri par sélection. Cette année, nous allons étudier un algorithme beaucoup plus efficace et très utilisé inventé par John Von Neumann en 1945: le tri par fusion. Cet algorithme nous permettra d’illustrer la méthode diviser pour régner que nous avions déjà vue lors de la recherche dichotomique.
1 Complexité des algorithmes de tri
En première, nous avons vu deux algorithmes peu performants:
- le tri par sélection qui a une complexité quadratique dans le pire des cas, le meilleur des cas et en moyenne.
- le tri par insertion qui a une complexité linéaire dans le meilleur des cas, et quadratique dans le pire des cas et en moyenne.
Ces algorithmes ne sont pas utilisés en pratique, car peu efficaces. En effet, il a été prouvé que dans le pire des cas et en moyenne, on pouvait au mieux obtenir une complexité .
Cela fait une grande différence car , en effet:
- pour
- pour
On avait déjà rencontré ce type d’améliorations entre la recherche en table et la recherche dichotomique qui utilisait le principe «Diviser pour régner».
2 Le principe de diviser pour régner
Le principe de diviser pour régner consiste à ramener la résolution d’un problème sur N données à la résolution d’un problème sur la moitié des données et poursuivre ce découpage jusqu’à ce que le problème devienne évident(par exemple trier un tableau d’une donnée). Une fois que les solutions des sous problèmes ont été trouvées, on les combine pour obtenir la solution du problème complet.
- Diviser : découper un problème initial en sous-problèmes ;
- Régner : résoudre les sous-problèmes (récursivement ou directement s’ils sont assez petits) ;
- Combiner : calculer une solution au problème initial à partir des solutions des sous-problèmes.
Article Wikipedia Diviser pour régner

{kind=link}
3 Le tri fusion
Le tri fusion s’appuie sur le fait que fusionner deux tableaux triés en un tableau trié se fait en un temps linéaire .
Pour fusionner ces deux tableaux triés:
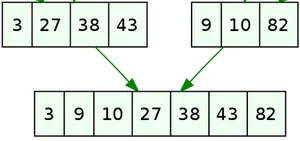
Il suffit d’une itération sur les deux listes en même temps donc ici 5 itérations pour une liste de 7 éléments:
- On considère 3 et 9, on place 3, et on avance sur la 1ère liste.
- On considère 27 et 9, on place 9, et on avance sur la 2e liste.
- On considère 27 et 10, on place 10, …
- On considère 27 et 82, on place 27, …
- On considère 38 et 82, on place 38, …
- On considère 43 et 82, on place 43, et on voit qu’on est arrivé au bout de la première liste On place maintenant tous les éléments restants de la deuxième liste.
D’autre part, le découpage récursif d’un tableau jusqu’à arriver au cas terminal : tableau trié d’un seul élément est en . Ce qui fait bien une complexité en , on ne peut pas faire mieux.
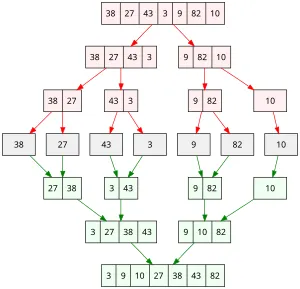
On va donc séparer notre algorithme en deux fonctions, une qui réalise la fusion et l’autre qui réalise la récursion du tri(le découpage). Ces deux opérations sont symbolisées sur l’illustration ci-dessous:
- rouge: division
- vert: fusion.
{kind=link}
3.1 Algorithme de fusion
Voici l’algorithme de fusion de deux tableaux triés en un seul.
Tout d’abord en pseudo-code:
fonction fusion(tbl1: Tableau, tbl2: Tableau)
// tbl1 et tbl2 sont deux tableaux triés
// Initialisation
i1 <- 0 // indice du 1er tableau
i2 <- 0 // indice du 2e tableau
tbl <- [] // liste vide destinée à accueillir les éléments triés
// Boucle
TANT QUE l'on a pas atteint la fin d'un des tableaux
SI tbl1[i1] <= tbl2[i2] ALORS
Insérer tbl1[i1] à la fin de tbl
incrémenter i1
SINON
Insérer tbl2[i2] à la fin de tbl
incrémenter i2
FIN SI
FIN TANT QUE
// Finalisation
// Insérer les éléments restants du tableau non vide à la fin de tbl
SI i1 < longueur de tbl1 ALORS
Insérer tous les éléments restants de tbl1 à la fin de tbl
SINON SI i2 < longueur de tbl2 ALORS
Insérer tous les éléments restants de tbl2 à la fin de tbl
RENVOYER tblEt voici une implémentation en python:
def fusion (tbl1: list, tbl2: list) -> list:
# Initialisation
N1, N2 = len(tbl1), len(tbl2)
i1 = 0
i2 = 0
tbl = []
# Boucle sur les deux tableaux
while (i1 < N1) and (i2 < N2):
x1, x2 = tbl1[i1], tbl2[i2]
# si x1 < x2 on ajoute l'élément x1 à tbl
if x1 <= x2:
tbl.append(x1)
i1 = i1 + 1
# sinon on ajoute l'élément x2
else:
tbl.append(x2)
i2 = i2 + 1
# Finalisation: On ajoute les éléments restants du tableau non vide restant
# Si tbl1 n'a pas été entièrement vidé, on ajoute ses éléments restants
if i1 < N1:
for i in range(i1, N1):
tbl.append(tbl1[i])
# Sinon on ajoute les éléments de tbl2 restants
elif i2 < N2:
for i in range(i2, N2):
tbl.append(tbl2[i])
return tblUn petit test dans la console ipython permet de vérifier sur un cas simple la fusion:
>>> fusion([3,6,8], [2,5,7,12])
[2, 3, 5, 6, 7, 8, 12]3.2 Algorithme de tri fusion
Voici l’algorithme récursif de tri fusion qui utilise la fonction fusion définie précédemment.
Tout d’abord en pseudo-code, on retrouve des techniques de découpage du tableau en deux avec des divisions
entières // vues dans la recherche dichotomique.
fonction tri_fusion(tbl: Tableau)
N <- Longueur de tbl
// Cas terminal: une liste de un élément est forcément triée
SI N == 1 ALORS
RENVOYER tbl
FIN SI
// Recursion sur les deux demi-tableaux sinon
tbl1 <- liste des N//2 premiers éléments de tbl
tbl2 <- liste des N//2 derniers éléments de tbl
// Renvoi des la fusion des deux tableaux
RENVOYER fusion(tri_fusion(tbl1), tri_fusion(tbl2))
Et voici une implémentation en python qui utilise les listes en compréhension:
def tri_fusion (tbl: list) -> list:
N = len(tbl)
# cas de base: un tableau de zéro ou un élément est forcément trié!
if N < 2:
return tbl
# on coupe le tableau en deux
tbl1 = [tbl[i] for i in range(N//2)]
tbl2 = [tbl[i] for i in range(N//2, N)]
# appels récursifs
return fusion(tri_fusion(tbl1), tri_fusion(tbl2))On fait un petit test sur une liste quelconque.
>>> tri_fusion([0, 25, 36, 41, 1, 465, 2, 3, 987])
[0, 1, 2, 3, 25, 36, 41, 465, 987]3.3 Conclusion
Nous avons vu dans ce chapitre un algorithme particulièrement élégant et efficace pour trier des éléments. Bien sûr, dans la pratique des contraintes de mémoire peuvent intervenir, et là au contraire cet algorithme se révélera peu performant, car l’utilisation de la récursivité et du tableau intermédiaire le rend très gourmand en mémoire.
La méthode «diviser pour régner» est une méthode très efficace pour résoudre des problèmes complexes en les découpant en sous problèmes indépendants. Par contre, on verra dans le prochain chapitre qu’elle devient inefficace si les sous-problèmes se chevauchent, et il conviendra alors d’utiliser une nouvelle technique appelée « Programmation dynamique » qui sera étudiée dans le chapitre P5C4.