Écrire un algorithme de recherche d’une occurence sur des valeurs de type quelconque
On montre que le coût est linéaire
Recherche dichotomique dans un tableau trié
Montrer la terminaison de la recherche dichotomique à l’aide d’un variant de boucle.
Des assertions peuvent être utilisées.
La preuve de la correction peut être présentée par le professeur.
Dans ce chapitre, nous allons étudier un algorithme très efficace de recherche d’élément dans un tableau:
la recherche dichotomique. Il illustre une méthode algorithmique très efficace et utile appelée: «Diviser
pour régner».
Commençons par créer une liste d’éléments pour cela nous allons écrire une fonction pour créer facilement des
listes de mots.
from itertools import productfrom string import ascii_uppercase as alphabetdef lister_mots(l=3):"""Renvoie une liste ordonnés de mots ayant l lettres"""return [''.join(lettres) for lettres in product(alphabet, repeat=l)]mots5 = lister_mots(5)# le nombre de noms générés est exponentiel par rapport à sa longueurassertlen(mots5) ==26**5print(len(mots5), "mots")print("Voici les sept premiers")print(mots5[:7])print("Et les sept derniers")print(mots5[-7:])
>>sortie
11881376 mots
Voici les sept premiers
['AAAAA', 'AAAAB', 'AAAAC', 'AAAAD', 'AAAAE', 'AAAAF', 'AAAAG']
Et les sept derniers
['ZZZZT', 'ZZZZU', 'ZZZZV', 'ZZZZW', 'ZZZZX', 'ZZZZY', 'ZZZZZ']
1 Algorithme de recherche dans un tableau non trié
Nous allons voir comment chercher une valeur dans un tableau par une méthode de parcours du tableau: la
recherche en table.
Cet algorithme naïf est couteux, mais on ne peut pas faire mieux si les données ne sont pas triées.
On parcourt l’ensemble du tableau et on s’arrête lorsqu’on trouve l’élément.
Dans une fonction le return est définitif, on peut donc facilement arrêter la
boucle dès que la valeur est trouvée. Si on est arrivé au bout de la boucle on est donc certains que l’élément
cherché n’est pas présent.
def recherche(élément, liste):"""Fonction de recherche de l'élément dans la liste Arguments --------- élement: str l'élément cherché l: liste la liste dans laquelle on cherche Retourne -------- bool True si l'élément est trouvé et False sinon """for e in liste:if e == élément:returnTruereturnFalse
Appelons la fonction sur un mot présent dans le tableau.
recherche("EULER", mots5)
>>sortie
EULER trouvé en 2186982 tours de boucle.
True
Regardons maintenant, si le mot n’est pas trouvé.
recherche("€UL€R", mots5)
>>sortie
€UL€R non trouvé en 11881376 tours de boucle.
False
2 La recherche dichotomique
Nous allons maintenant étudier l’algorithme de recherche par dichotomie. On peut comparer ça à une recherche
dans un dictionnaire (qui a eu la bonne idée d’être trié!)
2.1 Principe
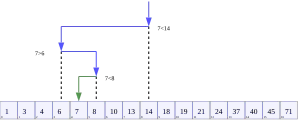
La recherche dichotomique ou recherche par dichotomie, est un algorithme de recherche pour trouver la
position d’un élément dans un tableau trié. Le principe est le suivant : comparer l’élément avec la valeur
de la case au milieu du tableau ; si les valeurs sont égales, la tâche est accomplie, sinon on recommence
dans la moitié du tableau pertinente. Source Wikipedia
def recherche_dichotomique(élément, liste): N =len(liste)# on initialise les indices début # et fin aux extrémités de la liste début =0 fin = N -1while début <= fin and fin < N:# On se place au milieu de la liste milieu = (début + fin) //2# il, s'agit d'une division entière# trois cas possiblesif liste[milieu] < élément: début = milieu +1elif liste[milieu] > élément: fin = milieu -1else:returnTruereturnFalse
2.3 Appels de la fonction
Recherchons le mot EULER de la liste.
recherche_dichotomique('EULER', mots5)
>>sortie
EULER trouvé en 23 tours de boucle.
True
Incroyable on a trouvé en 23 fois au lieu de 2186982 avec la recherche en table.
recherche_dichotomique('€UL€R', mots5)
>>sortie
€UL€R non trouvé en 24 tours de boucle.
False
24 tours au lieu de 11881376 dans le pire cas: le mot est absent.
L’algorithme de recherche dichotomique est incroyablement plus efficace que l’algorithme de recherche en
table.
Il s’agit d’un logarithme ayant une complexité en , c’est-à-dire le nombre de fois qu’il faut couper la liste en deux pour qu’elle ne contienne qu’un
élément.
Par exemple:
si n= :
si n= :
si n= :
si n= :
Au lieu de 11881376 d’opérations, on en effectue 24 au maximum!
3 Complexité temporelle
Comme on l’a vu, si on utilise un tableau trié, la recherche dichotomique est beaucoup plus efficace que la
recherche en table. Cela se traduit par un temps d’exécution infime en raison de sa complexité
logarithmique.

{kind=link}
{kind=link}